对前沿半导体感兴趣的人都知道,Intel最新的制造工艺已经跳票许久了。10nm工艺首次发布是在2014年,最初定于2016年量产,但却一直延期至今。虽然首批使用10nm工艺的移动处理器在2017年底出货,却是以“特供”笔记本电脑的形式与国内一些大学合作推出。
Intel的10nm处理器属于第8代酷睿系列,型号是i3 8121U。该处理器的ARK页面(Intel的在线数据库)已经公开,其核心代号为Cannon Lake,属于14nm Skylake核心的改良版,于2018年第二季度正式发布。
i3 8121U的TDP为15W,双核四线程设计,基础频率2.2GHz,睿频频率3.2GHz。这比同为15W的14nm Kaby Lake处理器甚至还要更低一些。最为新奇的是,虽然这是一颗移动处理器,却支持服务器和高端桌面平台处理器才有的AVX-512指令集,可以像企业级硬件一样处理向量运算。
i3 8121U的频率不进反退,让人们对Intel 10nm工艺的实际性能表现产生了丝丝疑虑。雷锋网从外媒SemiAccurate的一篇研究文章中获悉,目前(指i3 8121U推出时)Intel的10nm工艺还存在很多问题和困难,其收益只有10%,远低于预计中的60%,其中SAQP、COAG、Cobalt和调优等环节远远落后于计划和预期。
其后的几个月,坊间传闻Intel 10nm工艺严重受阻,甚至将要放弃10nm的研发工作,也有传闻称Intel将降低标准以实现这一制程,但都被Intel一一辟谣。好在今年的CES上,Intel展示了10nm工艺的全新Sunny Cove架构Ice Lake处理器,算是让关注新制程的人们吃了一颗定心丸。
虽然Ice Lake暂时还未落地,不过外媒Anandtech却通过各种渠道,弄到了使用Cannon Lake处理器的“特供”笔记本电脑,并对其进行了详细的测试。
10nm工艺难在哪?
2017年9月,Intel在技术与制造日上展示了一个10nm Cannon Lake芯片的完整300mm晶圆,外媒Techinsights测得该芯片的芯片面积约为70.5mm²,也就是说,i3 8121U是Intel迄今为止最小的双核处理器,但与当时的Skylake处理器(六代酷睿)相比,i3 8121U采用了CPU和GPU分离的设计,集成度更低。
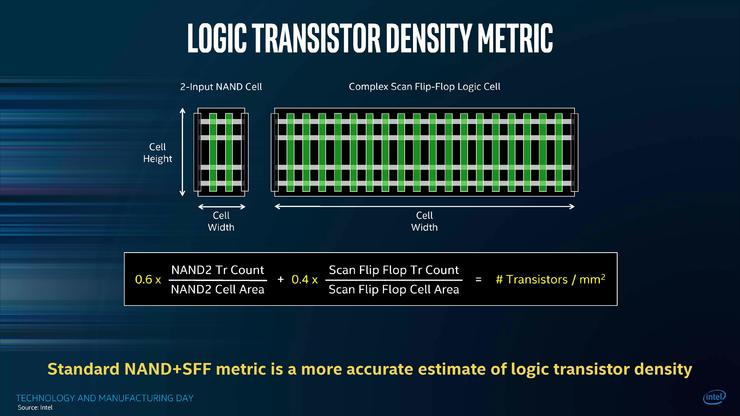
业内衡量半导体工艺好坏的常用标准之一,是芯片中每平方毫米集成度晶体管数量有关。CPU中并不都是运算晶体管,还有SRAM单元,以及一些被设计成区域间热缓冲区的“死”硅。晶体管的计数也有不同的方法,一个2输入的NAND逻辑单元比一个复杂的扫描触发器逻辑单元要小得多。
Intel将单位面积上的晶体管数量划分为2输入NAND单元和扫描触发器单元,其中2输入NAND单元的晶体管密度是90.78MTr/mm²(百万晶体管每平方毫米),扫描触发器单元的密度为115.74 MTr/mm²,在为其赋予60/40的权重后计算出10nm工艺的晶体管密度为100.8MTr/mm²,是14nm工艺37.5MTr/mm²的2.7倍。
Intel还在国际电子器件会议上披露,具体取决于所需的功能,10nm工艺的逻辑库有10种类型,包括短库(高密度库),中高库(高性能库)和高库(超高性能库)等。库越短,电路功耗越低,晶体管密度越高,但峰值性能也越低。因此Intel的10nm工艺其实有多种不同的密度,实际上只有密度最高的短库可以达到100.8MTr/mm²。
在实际芯片制造中,通常会混合使用多种库,较短的库适用于I/O和非核心区等对性能不敏感的部位以节约成本,较高的库通过较低的密度和较高的驱动电流,通常使用在对性能敏感的核心区域。
为了更好的理解Intel 10nm工艺,首先要讨论Fin(鳍)、Gate(栅极)、单元机制,以及定义与晶体管和FinFET相关的一些术语。
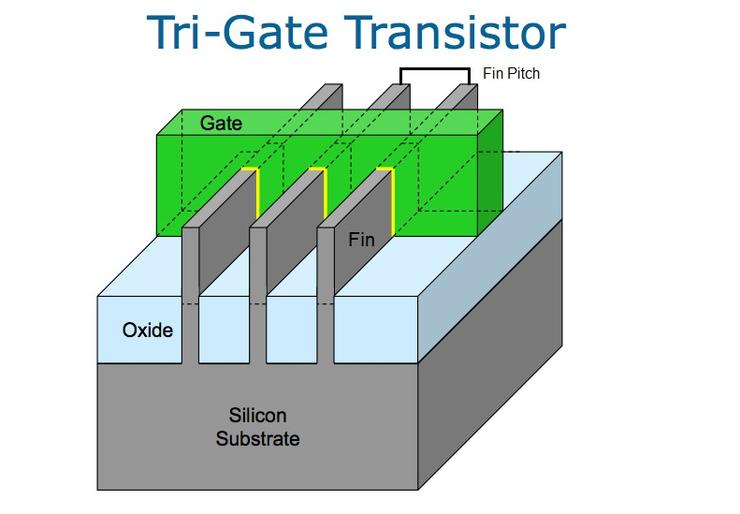
晶体管的源极-漏极由鳍(灰色)提供,该鳍穿过栅极(绿色)并嵌入氧化物中,这里的关键指标是鳍的高度、宽度和栅长,半导体工艺的目标是使每一个都尽可能小、单元性能尽可能高。
Intel在其22nm工艺中,使用了包含多个鳍片的三栅极晶体管来增加总驱动电流,以获得更好的性能。这就引入了一个新的度量:“鳍间距”,即鳍之间的距离。如果一个鳍通过了多个栅极,栅极之间的距离称为“栅极距”。
鳍和栅极之间接触的越多,鳍间距越小,泄漏就越低,性能也就越好,这可以增加驱动电流,也能控制寄生电容和栅电容。其后的14nm工艺中,鳍的高度、宽度和栅长都变得更短,每个鳍穿过的栅极也更多,因而获得了更好的性能。
而到了10nm工艺,Intel也在积极设计鳍结构,鳍间距从42nm缩减到34nm,鳍宽度从8nm缩减至7nm以避免寄生电容。改动看起来并不多,但在这个尺度上每nm都非常重要。Intel还通过添加共形钛层来改善源极和漏极扩散区域,鳍和沟槽之间的接触区域(栅极下方的灰色尖头)也需要让接触电阻最小化。在10nm工艺中,Intel将其从钨接触改为钴接触,使接触线电阻降低了60%,种种这些改进,让技术变得极其具有挑战性。
鳍与栅极组合起来就是基本的电路单元,从22nm制程的扫描电子显微镜的图像来看,单元有6片鳍的和2片鳍的(当然也有其他规格的),栅极长度不尽相同,每个单元内都有活跃的鳍传递电流和非活跃的鳍作为间隔。
在10nm工艺上,使用高密度库的单元总共有8个鳍,其中5个是活动鳍,这些单元可用于I/O等不需要很高性能或对成本敏感的电路部分。高性能库和超高性能库则分别有10个和12个鳍,各自相比前者多出一个额外的P鳍和N鳍,有助于提供额外的驱动电流,以适当的效率牺牲来换取峰值性能的提升。
在单元之间,通常会有许多作为间隔物的伪栅极。在Intel 14nm工艺中,每个单元的两端都有一个伪栅极,这意味着两个单元之间会有两个伪栅极。而在10nm工艺中,两个相邻的单元可以共享一个伪栅极,这将带来更大的密度优势,Intel表示最多可节约20%芯片面积。
晶体管内部,栅极通常靠两支长度略微超出单元尺寸的触点给源极和漏极加电,这不可避免的要占据额外的平面尺寸。在10nm工艺中,至少在目前Cannon Lake处理器使用的版本中,Intel通过一种被称为“有源栅极接触”(COAG)的设计,将栅极触点垂直放置在单元上。这一设计为制造过程增加了好几个步骤(一次蚀刻、一次沉积和一次抛光),但可以为芯片提供大约10%的面积缩放。
前文已经言道,外媒SemiAccurate上的一篇研究文章曾表示,COAG是一种风险较高的实施方案,虽然Intel已经把它造出来并且正常工作了,但它并不像预期的那样可靠。用于Cannon Lake核心的COAG似乎只能运行在低性能&低功率,或高性能&高功率的工况下,希望未来Intel能在新一代10nm Ice Lake处理器正式发售时详细说明关于COAG的改进情况。
回到晶体管密度上,衡量晶体管密度的另一种方法是CPP*MMP,即将栅间距(接触多晶硅间距Contact Poly Pitch)乘以鳍间距(最小金属间距)。种种这些改进加在一起,使Intel的CPP*MMP尺寸只有54nm*44nm,相比台积电和三星的7nm也只是略输一点点,这也是Intel一直强调前两者只是商业命名的原因。
揭开架构之秘
虽然i3 8121U的Cannon Lake核心仍处于NDA中,但经过科技圈众多同仁一年以来孜孜不倦的研究,终于还是基本揭开了其架构的面纱。
整体而言,Cannon Lake核心的设计很像是PC端Skylake核心与服务器端Skylake-SP核心的混合体。虽然它使用了PC端标准的4+1解码单元、8个执行单元以及L1+L2+L3缓存结构,但也从服务器端引入了一个AVX-512单元,并且L1数据缓存的读写速度分别达到了每周期2*512Byte和1*512Byte。
进一步来看,Cannon Lake核心也体现了一小部分第二代10nm Sunny Cove架构的设计,一些Skylake和Skylake-SP核心上没有的指令,在Cannon Lake和Sunny Cove上都有存在。
除此之外,虽然目前不太清楚Cannon Lake核心的架构前端设计变化,但还是可以看出重排序缓冲区的大小是与Skylake核心相同的224条微指令,而Sunny Cove架构的大部分特性改进(存储带宽加倍、执行端口更多以及执行端口功能改进)都没有出现在Cannon Lake核心上。
Cannon Lake支持的新指令包括IFMA(Integer fusion Multiply Add,整数融合乘加法)、VBMI(Vector Byte operation instructions,矢量字节操作指令),以及基于硬件的SHA(Secure Hash Algorithm,安全哈希算法)等。
其中,IFMA是52位整数融合乘法加法(FMA),其行为与AVX512浮点FMA相同,延迟为4个时钟周期,每个时钟周期的吞吐量为2(对于xmm/ymm/zmm为4和1)。该指令通常被用于辅助加密功能,但也意味着可以执行任意精度的算术运算。
VBMI指令集提供了VPERMB、VPERMI2B、VPERMT2B和VPMULTISHIFTQB四条指令,在字节混洗方案中非常有用。
而硬件加速SHA则纯粹是为加密算法加速而设计的,不过测试表明,Cannon Lake核心有了它后速度仍然比Goldmont(下代Atom处理器的核心)和AMD的Zen都慢,这意味着起码基于硬件的SHA在i3 8121U上并不是特别有用。
除了增加新指令,Intel通常还会在新核心上改进现有的指令,用于增加吞吐量或减少延迟(或两者兼而有之)。Cannon Lake核心还支持Vector-AES特性,它允许AES指令一次使用更多的AVX-512单元从而使吞吐量倍增。
在Cannon Lake核心上,最大的变化是可以硬件支持64位整数除法,不再需要分割成几条指令,18个时钟周期内就可以完成64bit的IDIV。相比之下,Zen执行同样的运算需要45个时钟周期,Skylake核心则需要97时钟周期。
对于字符串的块存储,所有REP STOS*系列指令都可以使用512bit执行写入端口,吞吐量为每时钟周期61bit,相比之下,Skylake-SP为43bit,Skylake为31bit,Zen为14bit。
对于全字整数矢量,AVX512BW命令VPERMW的等待时间从6个时钟周期减小到4个,并且每个时钟的吞吐量增加一倍。与向量类似,使用VMOVSS和VMOVSD命令移动或合并单/双精度标量的向量现在与其他MOV命令的行为相同。
对指令集的其他有益调整包括使ZMM划分和平方根更快一个时钟,并将一些GATHER函数的吞吐量从每四个时钟一个增加到每三个时钟一个;回归则以旧x87指令的形式出现,其中x87 DIV、SQRT、REP CMPS、LFENCE和MFENCE都变慢一了个时钟,其他指令则慢的更多,目的是让人们弃用这些老旧的指令。
Cannon Lake核心相对不足的地方包括:VPCONFLICT*命令具有3个时钟周期的延迟,吞吐量为每时钟周期一条,速度仍然很慢;DWORD ZMM表单的延迟为26个时钟,吞吐量为每20个时钟1个;不支持Skylake-SP核心的缓存行写回功能CLWB;不支持SGX(软件保护扩展)。
处理器规格对比
在i3 8121U的测试中,使用i3 8130U移动处理器作为对比,这是一款Kaby Lake核心的双核四线程处理器,使用14nm工艺制造,TDP同样为15W,基础频率与i3 8121U相同,睿频频率则反而要稍高一些。
对于这种15W TDP的移动处理器,会很容易撞上温度墙导致降频。测试中i3 8121U降频非常频繁,在AVX2应用中干脆是运行在2.2GHz的基准频率状态,AVX-512应用中甚至会降频至基准线以下的1.8GHz。
相比之下,使用14nm成熟工艺的i3 8130U在AVX2应用中仍能维持2.8GHz的频率,比如在POV-Ray测试项中,i3 8130U可以更快的完成测试,性能相比i3 8121U高出26%。
不过尽管i3 8121U在运行AVX-512应用时频率很低,但先进的指令集仍然带来了出色的性能,在3DPM测试中,开启AVX-512指令集的i3 8121U在1.8GHz下成绩为3846分,6倍于2.8GHz但只支持AVX2指令集的i3 8130U。
内存性能和功耗测试
在缓存/内存延迟测试中,i3 8121U和i3 8130U处理器都禁用了睿频,迫使它们以相同的2.2 GHz频率运行,以便进行奇偶性和直接的架构比较。Cannon Lake核心的缓存/内存子系统与Skylake核心相同的,没有任何其他改进,理论上表现出的性能也应该基本相同。
在这项测试中,两颗处理器的缓存访问延迟几乎相同,但Cannon Lake核心的i3 8121U的内存访问延迟要高出Kaby Lake核心的i3 8130U多达50%,一上来就震惊了四座(当然这不是啥好事)。
尽管为i3 8121U配套的DDR4 2400内存时序17-17-17,略输于i3 8130U的16-16-16 -16,但这一丢丢时序差异远不足以有如此大的影响,能想到的唯一原因是,Cannon Lake核心访问内存控制器有非常大的额外开销,这或许就是封堵了幽灵和熔断漏洞的副作用。
而功耗方面比较扑朔迷离,我们知道,Intel在处理器硬件中设置了两个关键的功耗限制——PL1和PL2,前者控制稳态功耗,后者控制短时间睿频功耗。
在大多数情况下,处理器的稳态功耗和TDP相同,如i3 8130U就是这样,处理器的稳态功耗为15W,然而同为15W TDP的i3 8121U的稳态功耗仅为12.6W。由PL2控制的峰值功耗也是同样,i3 8130U的峰值功耗可以达到24.2 W,而i3 8121U最高只能冲到18.7W,且睿频的持续时间也要比i3 8130U短很多。
糟心的是,虽然i3 8121U的功耗墙更低,但由于其频率更低性能更差,实际执行运算所消耗的能量反而更多。在POV-Ray测试项中,Kaby Lake核心的i3 8130U的总耗能只有768 mWh,而Cannon Lake核心的i3 8121U的总耗能为867mWh,足足高了12.9%。
2.2GHz同频测试:SPEC2006
除了功耗,关于Cannon Lake核心的另一个问题在于它是否是一个高效的架构设计。为了进行直接的IPC比较,我们将两颗处理器固定住2.2 GHz同频率上运行SPEC2006 测试。
SPEC2006是一个重要的基准测试软件,它与其他测试软件的区别在于所处理的数据集更大更复杂。作为基准测试更有代表性,它可以充分展示架构的更多细节。
从测试结果来看,两款不同核心的处理器性能相差无几,Kaby Lake核心的i3 8130U在与SIMD相关的462.libquantum和470.lbm测试项中似乎比Cannon Lake核心的i3 8121U更有优势,这也许与二者内存延迟性能有关。
2.2GHz同频测试:系统综合性能
系统测试部分重点关注实际用户体验,将包括应用加载时间、图像处理、简单科学物理、仿真、神经仿真、优化计算和3D模型开发等测试项。
GIMP应用加载时间
系统响应速度是最关乎用户体验的指标,一个很好的测试用例是看应用加载需要多长时间。在这一测试中,Cannon Lake核心的i3 8121U表现的特别好。
FCAT图像处理
FCAT软件采用录制的视频,并将颜色数据处理成帧时间数据,以便系统可以绘制可视化的帧率。
这一测试是单线程的,在基准频率下,Cannon Lake核心的i3 8121U与Kaby Lake核心的i3 8130U耗时差距在半秒之内,i3 8121U略微领先。
3DPM粒子运动计算
3DPM测试是一个定制的基准测试,旨在模拟3D空间中六个点的不同粒子运动算法。算法的一个关键部分是使用了相对快速的随机数生成,最终在代码中实现依赖链。在这一测试中,我们在六种算法上运行一个原子粒子集,每次20秒,暂停10秒,并报告粒子移动的总速率,以每秒数百万次运动为单位。
在不启动AVX,Cannon Lake核心的i3 8121U败给了Kaby Lake核心的i3 8130U。但各自启动AVX后,i3 8121U竟然跑出了4519的超高分,甚至击败了4185分的18核Core i9 7980XE处理器,非常疯狂。
Dolphin 5.0模拟器
Dolphin 5.0是一款GameCube/Wii主机模拟器,可以在PC上玩到这些老款游戏主机的独占大作。不过,模拟这两台使用Power架构处理器的主机通常需要一颗不弱的处理器才行。
在这一测试中,两款处理器的同频性能大致相同。
DigiCortex海蛞蝓大脑模拟
DigiCortex基准测试最初设计用于神经元和突触活动的模拟和可视化,该软件具有多种基准模式,本次使用小基准测试,模拟32000个神经元和18亿个突触,规模相当于海蛞蝓的大脑。
模拟类型分为“非激发”和“激发”两种模式,前者受内存影响更大,后者更依赖纯粹的处理器性能。测试中使用了后者,两款处理器的同频性能大致相同。
y-Cruncher科学计算
y-Cruncher是一款帮助计算各种数学常数的工具,软件支持通过二进制、单线程和多线程等不同优化方式运行,甚至包括AVX-512优化的二进制文件。本次测试基于单线程和多线程方式,计算2.5亿位圆周率。
测试结果不出意外是 Cannon Lake核心的i3 8121U获胜,到目前为止,所有可以利用AVX-512指令集的软件都是i3 8121U获胜。
Agisoft Photoscan 2D图像转3D模型
PhotoScan可以将许多2D图像转换为3D模型,这是模型开发和归档中的一个重要工具,依赖于许多单线程和多线程算法。
测试使用了PhotoScan v1.3.3版本,其中包含了84 x 1800万像素的大数据集,通过一个相当快速的算法变体,最后对比转换过程总时间。
在这一测试中,两款处理器的同频性能大致相同。
2.2GHz同频测试:渲染性能
渲染性能通常是处理器在专业环境下的关键指标,从3D渲染到光栅化,涵盖网格、纹理、碰撞、锯齿、物理等方面。大多数渲染器都支持CPU渲染,少数可以支持GPU或FPGA和ASIC等专用芯片。对于大型工作室来说,CPU仍然是首选的硬件。
Corona 1.3渲染
Corona是3DS Max和Cinema 4D等软件的高级性能渲染器,基准测试的GUI可显示正在构建的场景,并将渲染时间反馈给用户。
本次测试使用了直接输出结果的命令行版本,输出的结果也不是报告时间,而是报告六次运行中每秒的平均光线数,因为单位时间内的性能比例通常更容易理解。
Corona只支持到AVX2指令集,无法充分发挥Cannon Lake 核心的特性。在这一测试中,i3 8121U同频性能落后i3 8130U约10%。
Blender 3D创作软件
Blender是一个开源的高级渲染工具,支持大量可配置项,被世界上许多知名的动画工作室所使用。该软件的开发小组最近发布了一个基准测试包,本次测试通过命令行运行该套件中的“bmw27”场景子测试,并测量完成渲染的时间。
Blender同样只支持到AVX2指令集,在这一测试中,两款处理器的同频性能大致相同,Cannon Lake 核心的i3 8121U有微弱优势。
LuxMark引擎
使用LuxRender引擎开发的基准测试提供了几个不同的场景和API,本次测试选择在C ++和OpenCL代码路径上运行简单的“Ball”场景,以粗略渲染开始,并在两分钟内慢慢提高质量,最终结果以每秒渲染的光线数展示。
POV-Ray光线追踪
Persistence of Vision光线追踪引擎是另一个众所周知的基准测试工具,在AMD发布Ryzen处理器之前一直默默无闻,而后Intel和AMD都开始向开源项目的主要分支提交代码。
本次测试使用从命令行调用所有内核的内置基准。
2.2GHz同频测试:办公性能
Office测试套件旨在专注于更多行业标准,如办工流程和系统会议等,但是我们也将编译器性能捆绑在本节中。对于必须对硬件进行总体评估的用户来说,这些通常是最需要考虑的基准测试。
3DMark物理计算
游戏测试软件3DMark的每个测试场景均包括一个物理测试子项。按复杂程度排列的依次为Ice Storm、Cloud Gate、Sky Diver、Fire Strike和Time Spy。
在所有测试场景中,两款处理器的同频性能都大致相同。
GeekBench 4
GeekBench 4是常用的跨平台测试工具,重点寻求峰值吞吐量的一系列算法,包括加密、压缩、快速傅里叶变换、存储器操作、n体物理、矩阵运算、直方图处理和HTML解析等,常用于移动设备测试。
考虑到其通用性和流行程度,本次也加入了这款软件的单线程和多线程测试。
2.2GHz同频测试:编码性能
随着流媒体和短视频内容的兴起,越来越多的家庭用户和游戏玩家需要将视频文件进行转换,处理器的编码和转码性能变得越来越重要,本次编码测试也主要围绕这些重要的场景进行。
Handbrake视频转码
Handbrake是一种流行的开源视频转换软件,最新的版本可利用AVX-512和OpenCL来加速某些类型的转码和算法。本次测试使用的CPU转码。
7-Zip压缩解压
在压缩/解压应用中,开源的7-Zip是很欢迎的工具之一。本次猜测是使用最新的v18.05版本,它内置有基准测试,从命令行运行基准测试,报告压缩、解压缩和综合得分。
WinRAR压缩解压
在大多数人的系统中通常都有WinRAR,它是20多年前的第一批压缩解压工具之一。它没有内置基准测试,本次使用一个包含超过30个60秒视频文件和2000个零碎小文件的文件夹,以正常压缩率运行压缩。
WinRAR是可变线程的,但也容易受到缓存的影响,因此测试需运行它10次并取最后五次的平均值,使结果可以展示CPU纯粹的原始计算性能。
AES加密
许多移动设备默认使用的文件系统都提供了加密功能以保护内容,PC上的Windows也有,通常由BitLocker或第三方软件应用。本次使用已停产的TrueCrypt作为其内置基准测试,可直接在内存中测试多种加密算法,支持AES指令集但不支持AVX-512。测试采用的数据是AES加密/解密组合,以每秒千兆字节为单位。
雷锋网总结
Intel在10nm工艺上确实进行了很多改进,如果每一步都能完美运行,那么10nm应该在去年就成了。可问题是在半导体设计中,有几百个不同的特性,改动任何一个都可能会导致其他几个甚至几十个特性变差,这正是Intel在10nm工艺方面遇到的最大问题。
仍记得2018年的CES上,Intel对10nm工艺相关的问题缄口不言,从这昙花一现的Cannon Lake核心来看,唯一称得上亮眼的表现只有AVX-512性能,很明显第一代10nm还远远没有准备好迈入黄金时段,Intel是在试图冷处理这一代处理器,也肯定不会正式公开发售它们。
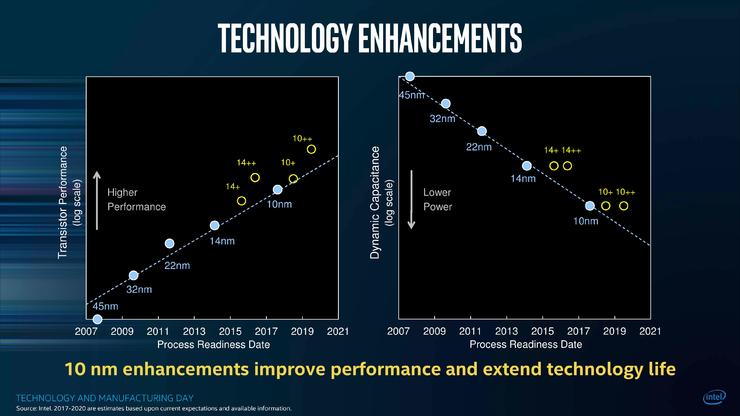
在Intel给出的这张图中,右侧显示10nm工艺及其改型可依靠较低的动态电容拥有较低的功率,然而数轴的左侧则显示10nm和10nm+工艺的单个晶体管性能其实还要低于当前的14nm++工艺,要到下下下一代的10nm++工艺才能真正实现全面领先,而从i3 8121U的表现来看,很大概率上也意味着在第三代10nm++工艺实施之前,业界很可能都无法看到真正突破性的10nm处理器(一竿子支到三零零零年了……)。
预计将在今年下半年问世的Ice Lake处理器会使用第二代10nm+工艺,电气性能将非常接近14nm++工艺,或许那时Intel在10nm工艺上打响真正的第一炮吧。